Survey - Target Audience

Our group Patched studios conducted a survey as part of our research regarding the Fairytale AI client project. In this survey. We will gather as much valuable data and feedback from participants. By doing this we will gain a deeper understanding on what our target audience wants and their expectations to develop an user-friendly platform for our client project application.
Process
To understand what we want to achieve for the survey we’ve made a research document where we analyze our main and secondary questions. This document was a follow up of the previous researches we have conducted. To conduct this survey I’ve made use of the CMD method Field – survey.
Our goal of this survey was to figure out “Who is our target audience?” To get started I’ve made a survey in Google Docs that consisted of 6 sections. Each section has its own purpose:
Section 1: This section had an opening question, here I asked if the participant is still reading aloud to children. If they answered “yes” would, they will be directed to 2nd section and to the 6th if they answered “no”.
Section 2: Here I’m asking the participants some general questions such as their age, nationality and how much kids they have.
Section 3: In this section I’m asking the participants how much and how often do they read aloud to their children and the type of stories.
Section 4: This is about the disabilities of their child and whether the participant is taking that into account.
Section 5: This section is about which devices the participants are using often in their day-to-day basis and which genres do they prefer for their children to read with.
Section 6: This section is a follow up of section 1, incase the participant isn’t reading aloud to their children. They can explain here why they aren’t doing it.
The questions in these sections are not only multiple choice, but the participants could also give their input on them. I did choose Google docs, because it was flexible to use, since it can she shared using a link while keeping the participants identity private and safe. Eventually once the we gathered enough data, we’ll convert them into graphs which makes it us easier to implement them during our client presentation and to write about them in our research documents.
My other 3 members of Patched studios and myself shared the survey within Fontys, but also to colleagues from work, friends and families. I went a step further and did share it on an online community platform called Discord, I think this will benefit us even more. We did receive sufficient data from our participants to make me prepare for the next phase.
Results
Here are some of the notable results from the survey that we’ve conducted as a group that will be crucial for us in the future in developing the application.
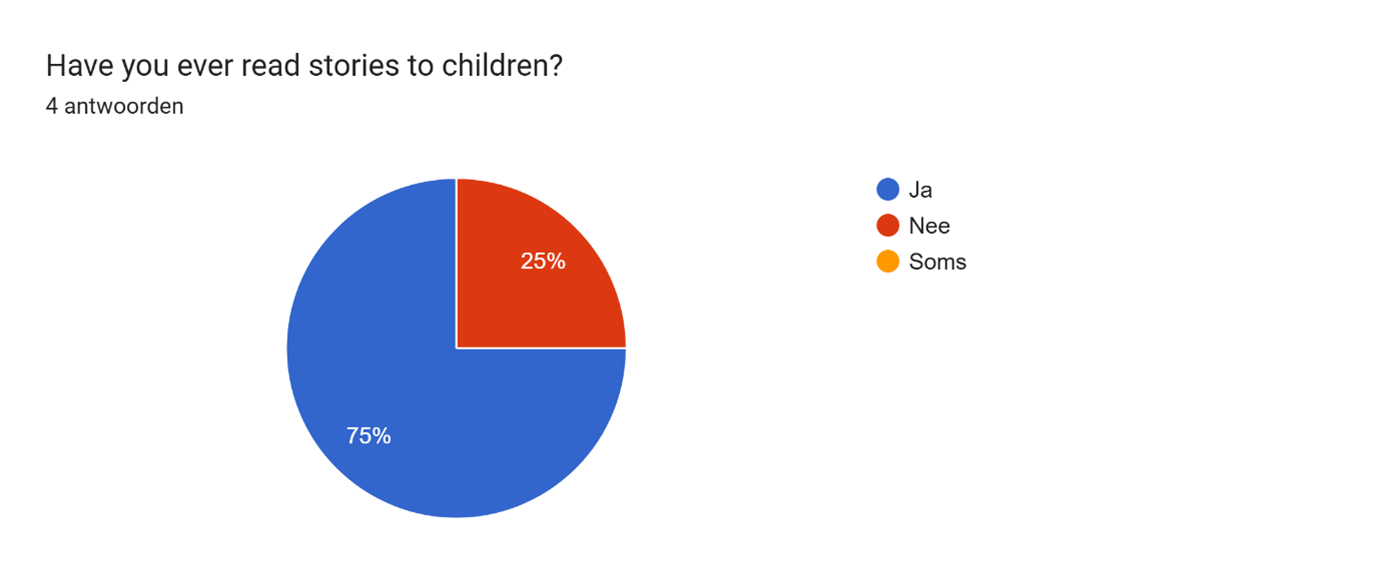
1. This graph shows that a large portion of the participants still reads stories to their children. Our goal is to make their experience.
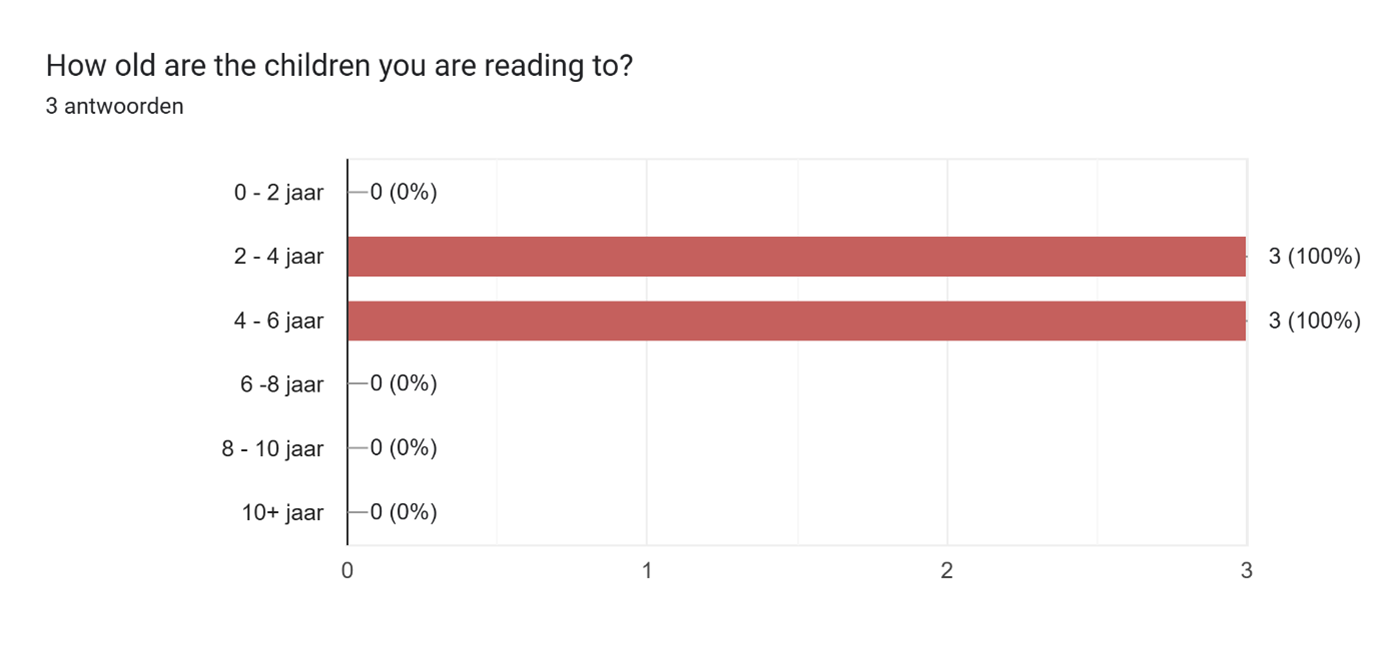
2. This graph shows the age group of the children they’re reading aloud with. It falls in the age group that we aimed for, which is between the age 2-8.
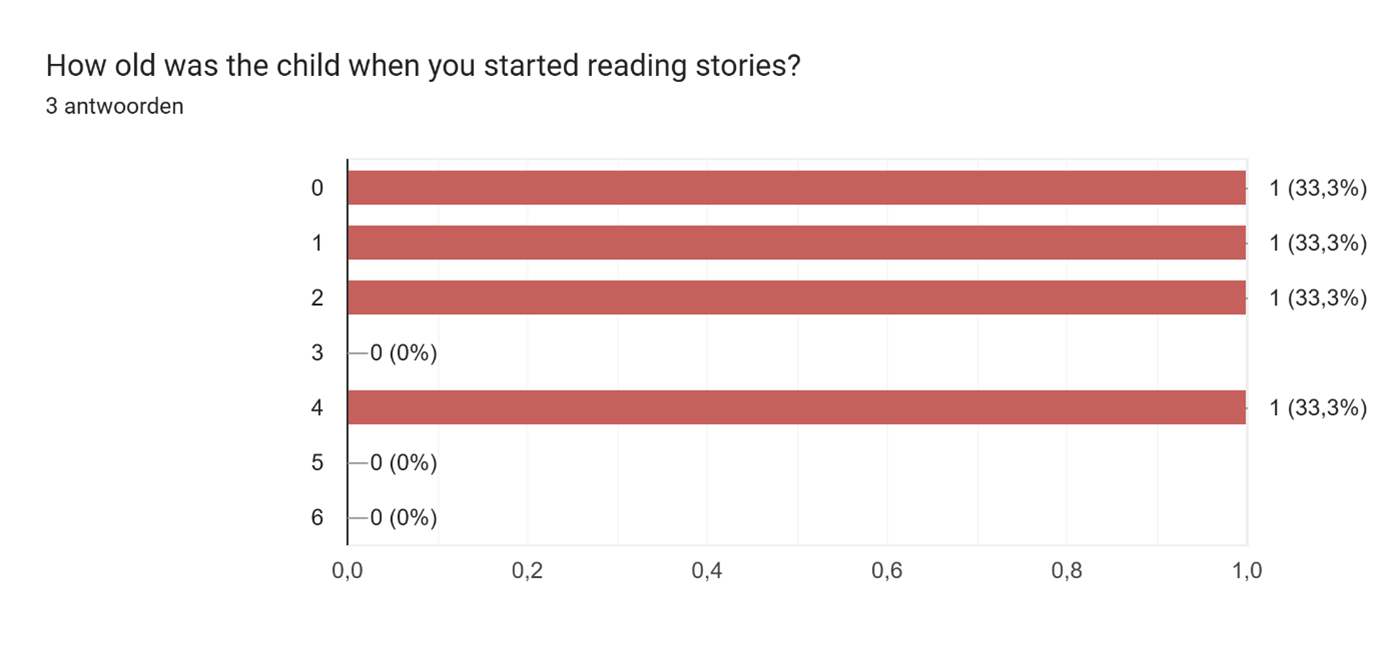
3. This graph highlights that the participants read stories at a different age, some start at birth while others start reading when the children are much older.
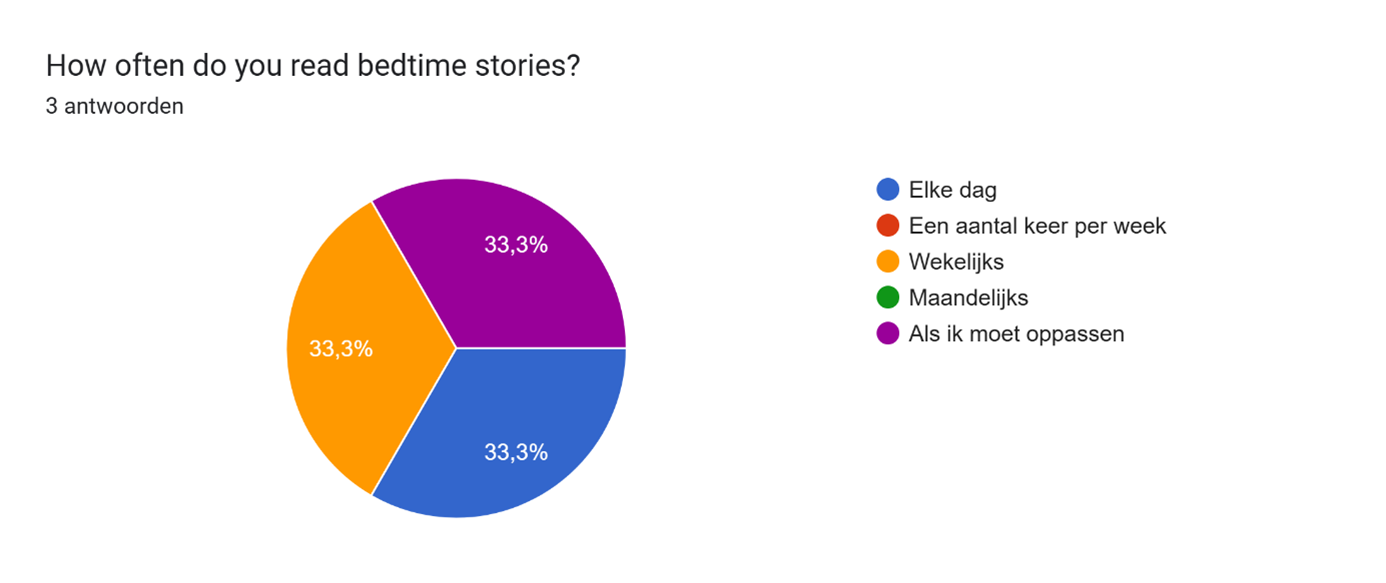
4. This was another graph that stood out from others, because every participant has their preference when they read bedtime stories. This is because every participant isn’t always available in their own day-to-day lives at certain times. So they’re reading when it suits them.
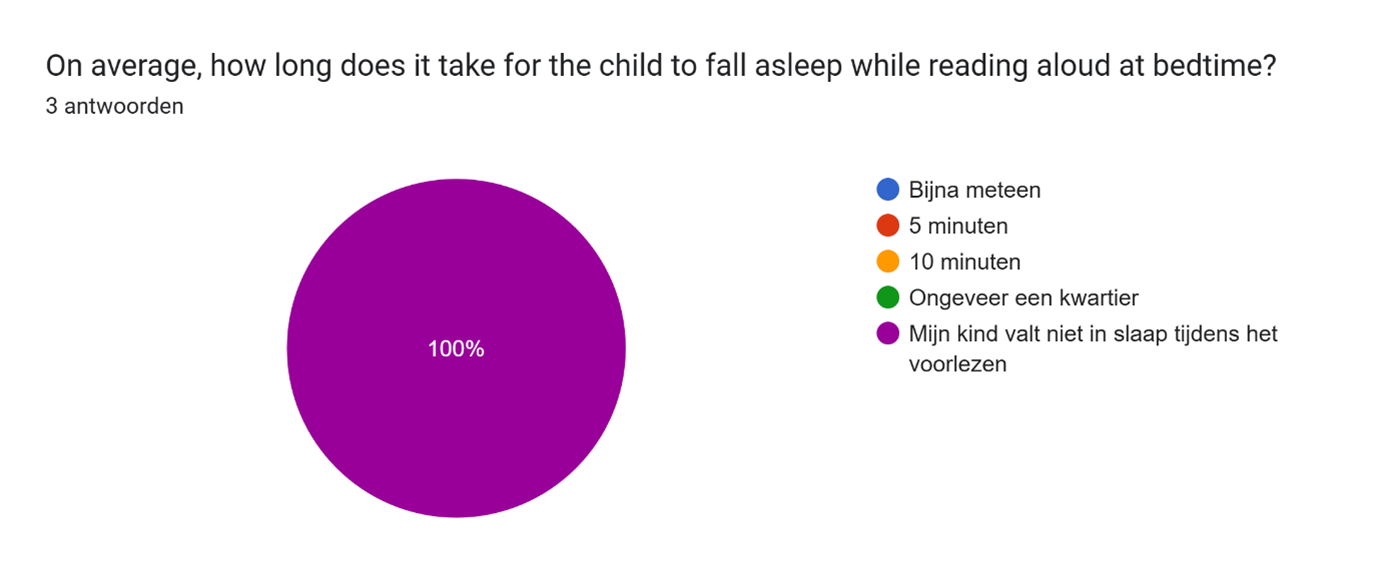
5. This graph clearly reveals to me that bedtime stories that are currently being read to children aren’t really helpful for children to make them fall asleep, but mostly for entertaining the children instead.
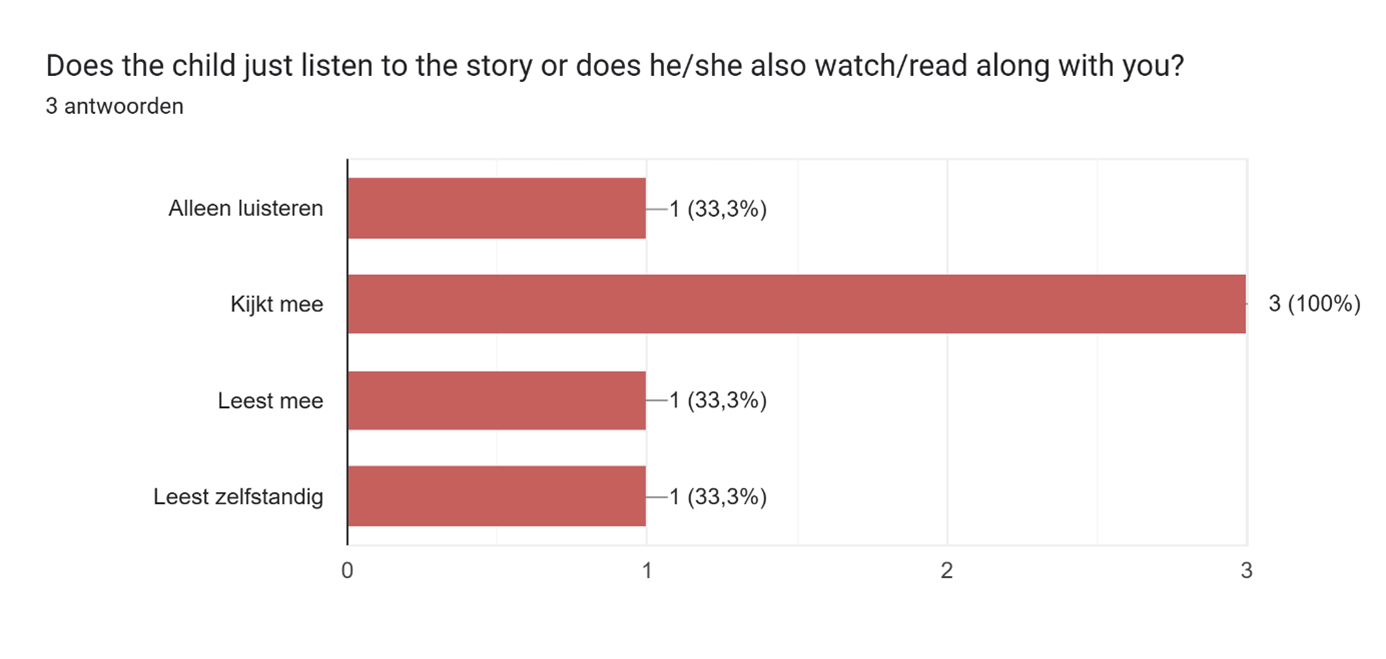
6. This graph showcases that majority of the children prefer to watch the whole story with an adult, probably the visuals such as the pictures that are being displayed during the story progression.
Reflection
This survey research was an important step in our project, allowing us to gather insights into our target audience’s preferences and expectations for our personalized AI story generating application for the client project.
Moving forward, with this data we will remain aligned with our target audience and what they are expecting in their product, this allows me to work on the first iteration of my wireframe that I will soon make accordingly based on the data I’ve received from this survey.
The results that I’ve collected here will be written in the concept research document, where are our other upcoming researches will be collected there as well. I will also begin on conducting library research.